البحث الهجين
دمج قوة البحث السياقي والمفتاحي لتحسين تجربة البحث
مقدمة
لفترة طويلة تجربتي باستخدام محرك البحث داخل اي تطبيق بودكاست كانت سيئة ونادر القى الشي اللي ابيه بسهولة. وطرت ببالي فكرة بيوم من الايام شنو بيصير لو صار البحث معنوي بحيث يعتمد على المعنى والمقصود اكثر من الكلمات المفتاحية المستعملة، كيف بتكون النتايج وكيف بتكون التجربة؟ غوص معي بذا المقالة وخل نشوف شصار.
سياق
عشان نعرف كيف ممكن البحث يصير معنوي، مهم نتعرف على تقنية مهمة جدًا: المتجهات (Vectors) والتمثيلات (Embeddings). خل نتكلم عنهم ونفهم ليش هم مفيدين بامور كثيرة جدا.
المتجهات والتمثيلات
زبدة المتجهات هي بكل اختصار تمثيل رياضي للكلمات، يعني بختصار تحويل الكلمة لارقام تكون مفهومة للآلة. وهذا التمثيل الرقمي للمتجه نناديه بالتمثيلات. وهذي فكرة موجودة من زمان بالذكاء الاصطناعي، بدت بطرق بسيطة للتمثيل مثل استعمال العد وطرق ابسط اخرى لكن ذي الطرق فيها مشاكل كثير: صعب تمثل المعنى، اختلاف الكلمات يؤدي لمشاكل والخ...
فسرعان ماتحول الموضوع واصبحت العادة انه ندرب نموذج ذكاء اصطناعي وظيفته فقط التمثيل بافضل طريقة، وعادة المقصود بالتمثيل بافضل طريقة اننا نبي النموذج يجمع الاشياء المتشابهه بالمعنى حول بعض ويعرفهم او بمعنى اخر يبدا يفهم العلاقات الدلالية والسياقية ويبدا يمثل العلاقات اللغوية بشكل ممتاز.
ملاحظة: التمثيل ما يقتصر على اللغة فقط ويستعمل بامور كثيرة مثل الصور وغيرها.

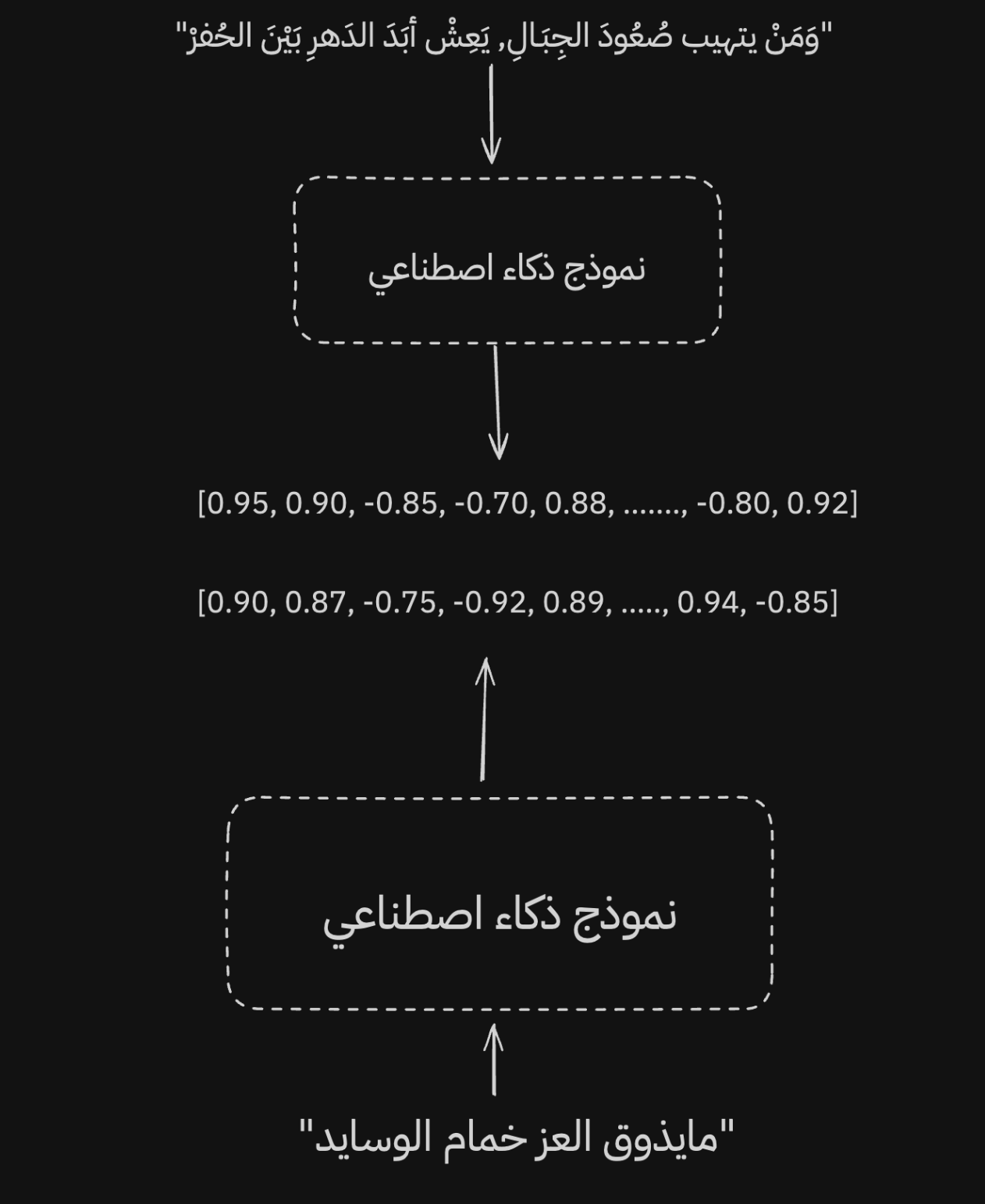
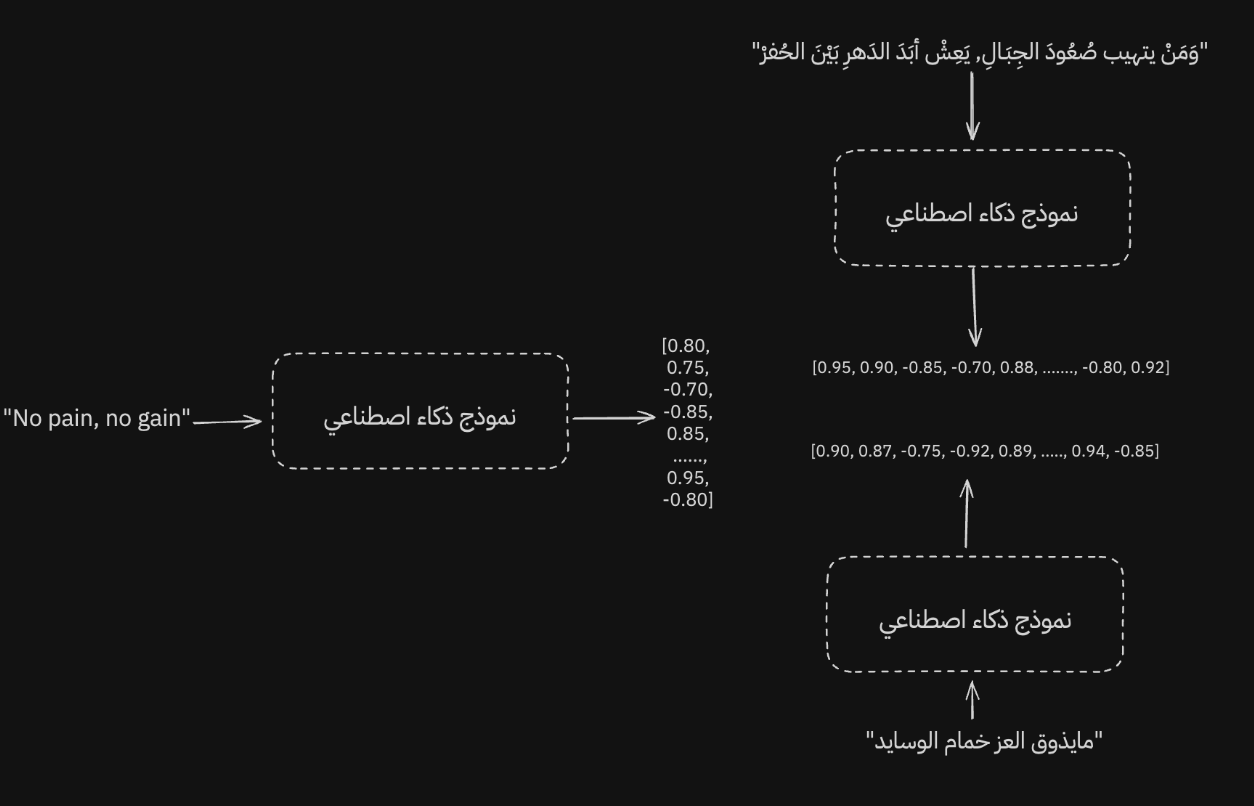
ومو بس كذا، كذلك يقدر النموذج حتى لو استعملنا لغة اخرى يبقى يعطي تمثيل مقارب للجمل الاخرى.
وطبعا الطريقة الى ان يكون النموذج ممتاز باكثر من لغة بانه لما ندرب النموذج نحرص ان ذا الشي يكون بعين الاعتبار وتكون بياناتنا والمفردات اللي يدرب عليها النموذج كبيرة، ف لذلك مهم معرفة ان مو كل النماذج بمدربة بهذا الهدف، فيه نماذج تكون مخصصة للغة الانقليزية فقط واداءها يسوء باللغات الاخرى لان ماتم تدريب النموذج لذا الهدف.
خل نتكلم الان عن بعض المزايا الناتجة عن التمثيلات بفضاء التمثيلات (Embedding Space).
فضاء التمثيلات
من اليوم وحنا نسولف عن تمثيل المعنى، طيب كيف يصير ذا الشي فعليًا وكيف نفسر ونفهم نتائج النموذج؟ خل نشوف الصورة ونبدا نحللها.
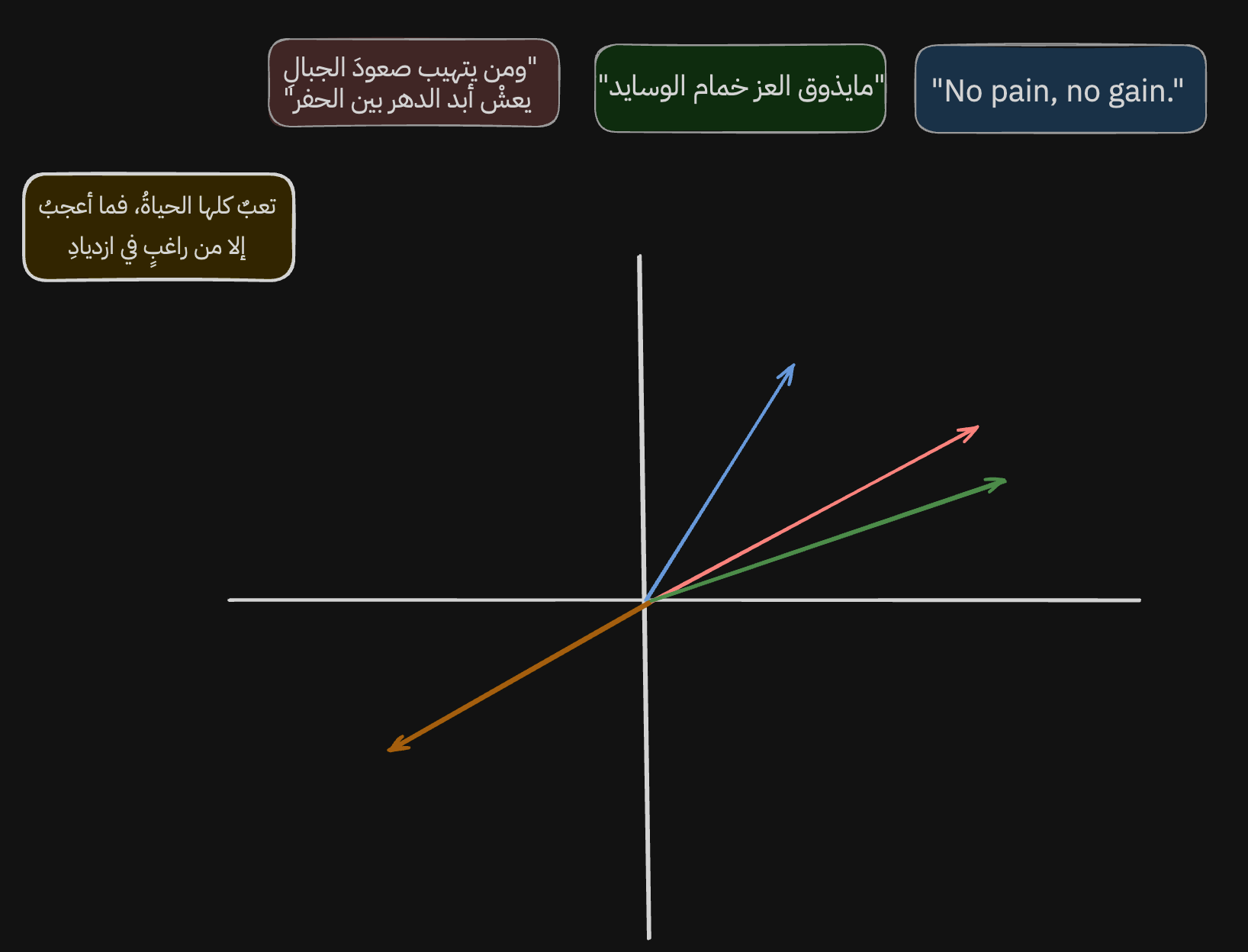
لما ناخذ التمثيلات اللي عطانا اياها النموذج مسبقًا ونمثلها بالمحور السيني، بتطلع لنا بذا الطريقة (ملاحظة مهمة: هذا تبسيط لناتج النموذج لأن فالعادة التمثيلات اللي تطلع من ذي النماذج تكون بابعاد عالية جدًا كبشر مانقدر نستوعبها، لذلك بسطت الناتج وخليته فقط على بعدين الا وهم ال(س) وال(ص) عشان نستوعبها ونفهمها بشكل اسهل).
معلومة: [-24, 420, 2.4, ...] كل رقم داخل التمثيل هو بُعد ف كل ما ضفنا رقم كل ما ضفنا بُعد جديد.
خل نبدا نحلل، لو نشوف الناتج اللي طلعنا نلقى ان الجمل اللي اخترناها مجمعة حول بعض وقريبين من بعض، ونقدر نقيس شكثر قريبين من بعض باستخدام اكثر من طريقة رياضية اشهرها الCosine Similarity اللي تقيس الزاوية مابين المتجهين وكل ماكانت ذي الزاوية صغير كل ماكان المتجهين متشابههين. ف مثلًا لو كانت الدرجة مابينهم 12º, ف ناتج ال cos(12º) بيكون 97.8% ولما تكون الزاوية عمودية أي 90º يكون التشابه 0% والخ..
لكن الشيق بناتج التمثيل هو مو بس سهولة قياس التشابه السياقي بين الجمل، هو ان النموذج يتعلم يمثل كذلك اختلاف المعاني باختلاف الاتجاه، خل نوضح وش نقصد.

لو نشوف الاسهم الرصاصية، نشوف ان النموذج تعلم يمثل ويجمع الجمل اللي تتكلم عن الاجتهاد والكرف لاجل العز والعظمة بهذا المكان وهذا الاتجاه
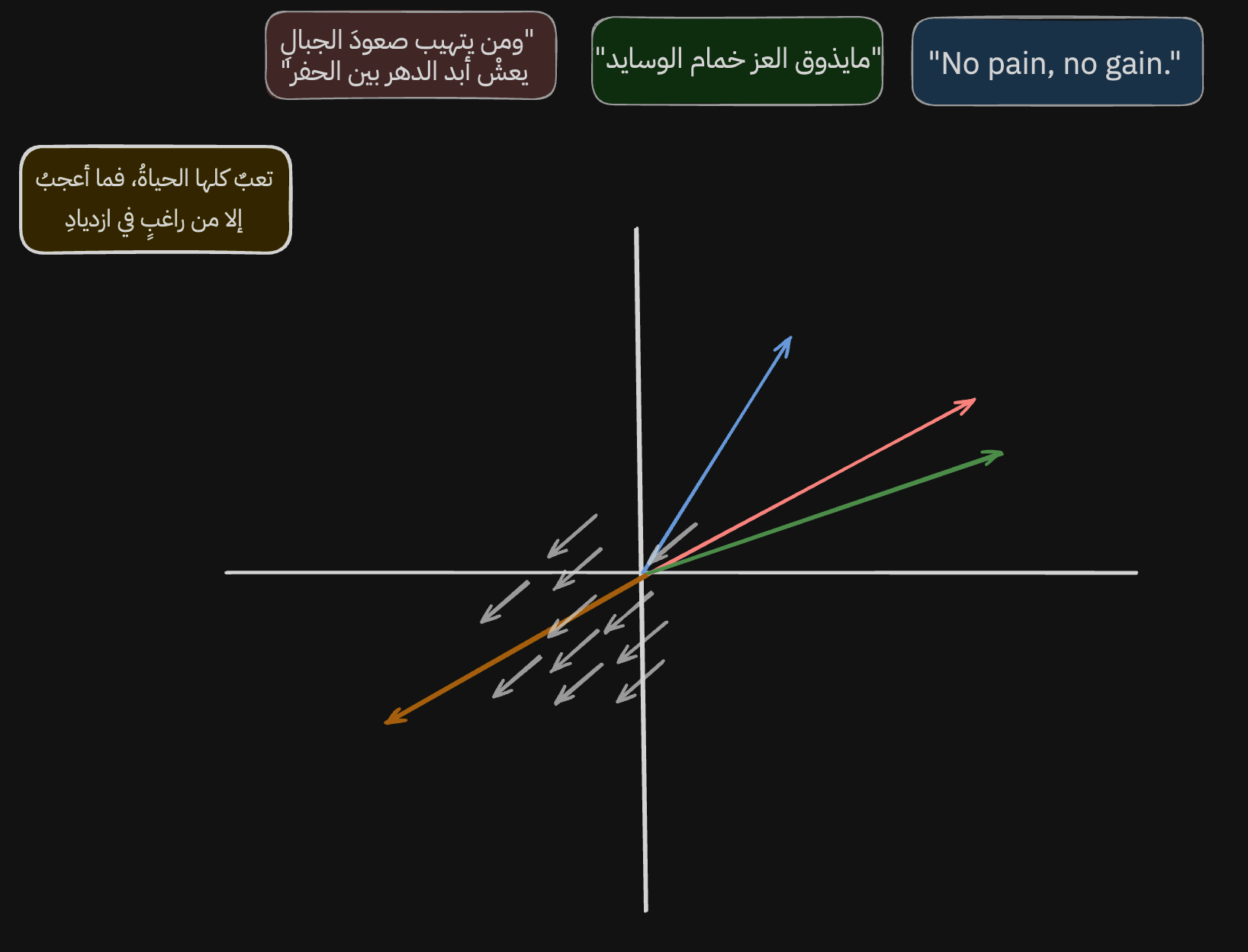
ولو نشوف البيت الجديد نلقى ان النموذج كذلك تعلم يمثل فالاتجاه المعاكس الجمل اللي تتكلم الهزيمة والانكسار والكسل.
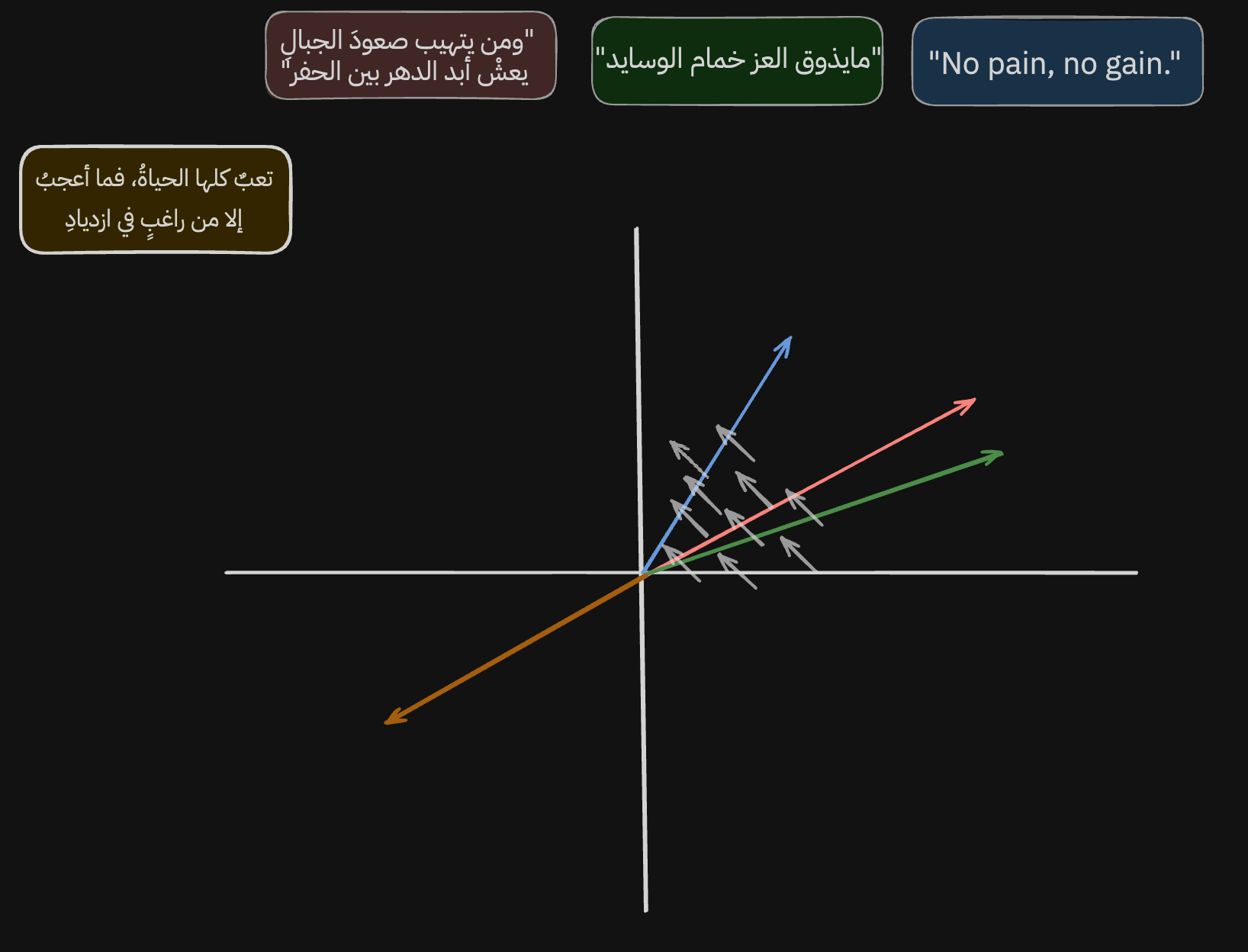
ومو بس كذا نلقى ان النموذج بهذي الصورة وهذا الاتجاه تعلم يمثل ويجمع تحول اللغة من عامية الى فصيحة الى انقليزية.
ف هذا جزء بسيط من قوة المتجهات والتمثيلات ف فهم هذي الفكرة يمكننا من استخدامها بحلول كثيرة جدا بنشوف اليوم كيف نقدر نقوي ونعزز البحث التقليدي اللي يعتمد على الكلمات المفتاحية بالبحث السياقي وننتج بحث يمزج مابين الكلمات المفتاحية والمتجهات اللي تساعدنا على تمثيل السياق.
صورة اخرى لزيادة الفهم:
محرك البحث
طيب قبل لا نبدا في في البناء، خل نحط لنا كذا قاعدة ومتطلب اساسي.
- محرك البحث لازم يمزج مابين البحث بالكلمات المفتاحية والبحث السياقي، ليه؟ لان البحث السياقي يعتمد على المعنى ولا يعتمد الكلمة كحد ذاتها ف احيانًا مايكون الافضل لما نبحث عن شي دقيق، خل ناخذ كم مثال سؤال والناتج له. (لنفترض عندنا ردود محفوظة والبحث وظيفته يرد الرد الاصح)
السؤال: "المادة رقم 13 من نظام الشركات السعودي."
البحث المفتاحي: "تنص المادة 13 من نظام الشركات على أنه...".
البحث السياقي: "يتضمن النظام العام أحكاماً تتعلق بالشركات ذات المسؤولية المحدودة...".
نشوف هنا ان البحث المفتاحي جاب لنا الاجابة الافضل لانه يركز على التطابق بينما البحث السياقي فشل رغم انه جاب شي قريب بالمعنى.
السؤال: "ألم جهة القلب لكن مو القلب."
البحث المفتاحي: "النوبة القلبية تسبب ألماً في الصدر...".
البحث السياقي: "قد يكون الألم في الجهة اليسرى ناتجاً عن مشاكل في المعدة أو العضلات، وليس القلب."
هنا نشوف البحث المفتاحي يفشل بالجواب لانه يعتمد على التطابق ومو فهم السياق فنشوف البحث السياقي هو اللي يعطي الاجابة الصحيحة كذلك البحث السياقي ماعنده مانع بالاخطاء الاملائية على غرار البحث المفتاحي.
ف كلًا من طرق البحث له مزاياه وسلبياته والشي اللي ودنا نعرف جوابه: وش يصير لا دمجتهم مع بعض؟
- محرك البحث لازم يكون كويس باللغة العربية \*طبعا\*
- مهم نحاكي الواقع ف غالبًا فالـ Production وخصيصًا اننا بنمثل حلقات بودكاست واللي يعتبر عددها ضخم جدًا فمثلا الPodcastIndex عنده اكثر من 100 مليون حلقة. فمهم النموذج يكون: رخيص، صغير وسريع.
وخل نبدا.
1. تحميل البودكاست والحلقات محليًا.
ف هذي الخطوة بستخدم الـ [PodcastIndex](https://podcastindex.org/)، ووش هو؟ هو قاعدة بيانات لامركزية ،مفتوحة تجمع فيها البودكاستز ويوفرون API سهل وبسيط. فراح نسحب هذي البيانات لقاعدة بيانات عندنا.
(راح اشارك امثلة بسيطة من الكود فقط عشان المقالة ماتصير حوسة، الكود باكملة مفتوح المصدر ويمديك تشيك عليه بهذي [الريبو](https://github.com/Mamdouh66/better-search))
for query in queries:
search_results, search_raw = search_podcasts(index, query, clean=True)
...
ف السكربت اللي موجود ف scripts/load_from_index.py يسحب البيانات عن طريقين واحد عبر Queries او بختصار بودكاستات معينه ابيها تكون موجودة بالبيانات غصب وبنعرف ليه شوي.
الطريقة الثانية اننا نسحب البودكاستز الرائجة وتحت تصنيفات معينة (لسبب ما يحط بودكاستز محد يدري عنها كرائجة وعشان كذا بحث منفصل عن Queries معينة).
# These are from https://api.podcastindex.org/api/1.0/categories/list?pretty (Auth needed)
top_podcast_categories = {
"News": 55,
"True Crime": 103,
"Comedy": 16,
"Society": 77,
"Culture": 78,
...
}
for cat in top_podcast_categories:
trending_results, trending_raw = get_trending_podcasts(
index,
language=[lang],
max_results=50,
categories=[top_podcast_categories[cat]],
since=timestamp_2024_01_01,
)
...بعد ما نسحب البيانات ونرفعها بقاعدة بيانات محلية ننتقل للجزء الشيق واللي هو تمثيل وترميز هذي البيانات.
قبل ما نبدا مهم نتكلم عن نوع مختلف من قواعد البيانات الا وهي قاعدة بيانات المتجهات (Vector Databases) وهي بختصار قاعدة بيانات تكون مبنية من الاساس عشان تكون مثالية للتعامل مع المتجهات. وعشان نفهم الفرق بشكل الافضل ممكن نشوف الصورة التالية.
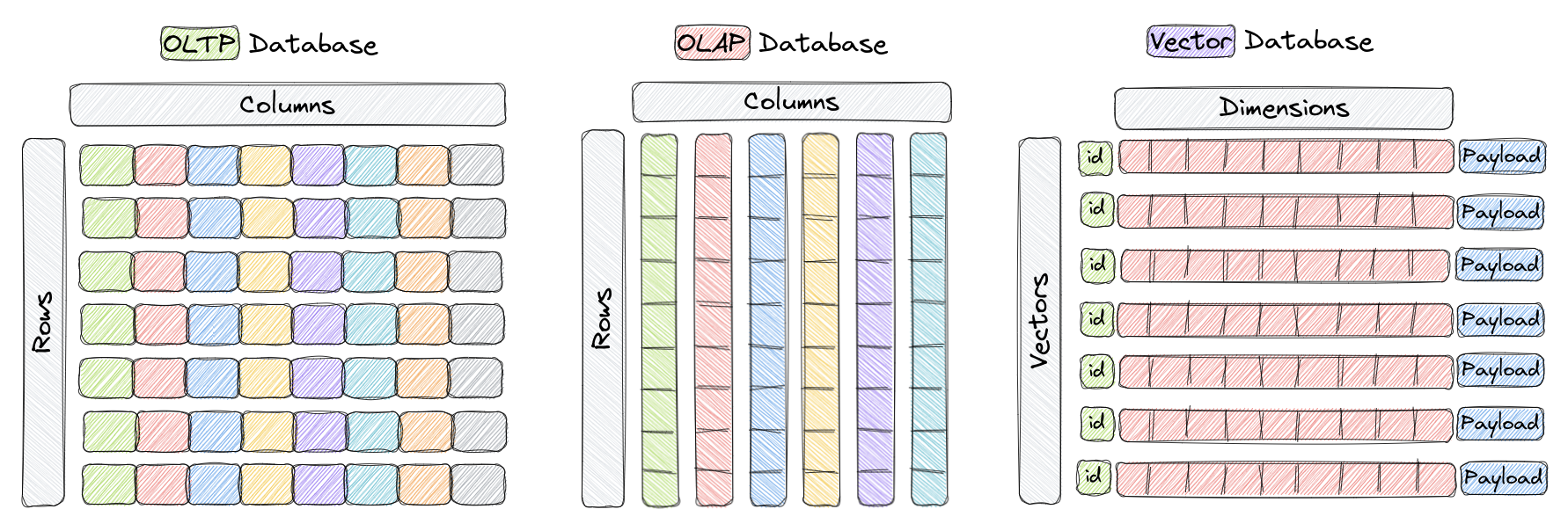
نشوف بذي الفرق مابين الOLTP وهي النوع المعتاد والمتعارف عليه من قواعد البيانات مثل Postgres واللي تكون هيكلتها البيانات تجمع كصفوف ولها ميزاتها مثل سرعة الادخال والقراءة ولها سلبياتها مثل عدم الكفاءة بالتحليلات والمعادلات الرياضية. وفيه الOLAP اللي هيكلتها ان البيانات تحفظ كاعمدة وتمتاز بانها عالية الكفاءة للتحليلات والعمليات الحسابية بشكل عام لان تخيل عندنا 1000 عمود واحتجنا نسوي حوسة رياضية معينة لما نجي نقرا البيانات بالOLTP بنضطر ننادي كل الأعمدة عشان نجيب البيانات اللي نحتاجها وذا طبعا شي غير مثالي لانه يكون ابطئ وياخذ مساحة اكثر، لكن الOLAP لان البيانات تحفظ كاعمدة يمدينا نسحب البيانات اللي نبيها فقط بالاعمدة اللي نحتاجها للعملية الحسابية وذا الشيء اكفئ بمراحل وطبعا له سلبياته واللي هي انه يكون ابطئ بالادخال والقراءة.
وهنا يجي النوع الجديد وزي ماهو موضح بالصورة مهيكل بانه يكون مثالي للتعامل مع المتجهات فماهو معرف كصفوف واعمدة بل بمهيكل بطريقة مختلفة وعشان اشرح الطريقة هذي بشكل مبسط خل اتكلم عن القاعدة اللي بنستعملها الا وهي [Qdrant](https://qdrant.tech/) طبعا فيه قواعد كثيرة وكلٌ لها مزايها وحلاة حقتها ان تجربة المطور فيها افضل والدوكمنتيشن حقتهم ممتازة كذلك اداءها ممتاز.
كيف Qdrant تشتغل تحت الستار بشكل مبسط جدًا؟
عندنا خيارين اذا ودنا نحفظ البيانات on disk او لا. الافتراضي انه لا واللي يصير هنا ان المتجهات تكون بالذاكرة (RAM) طوالي والPayload(metadata) كذلك بالذاكرة واللي بيكون سريع جدًا لكن غير مثالي عمليًا.
ف لما نختار انها تكون on disk المتجهات بيكون محفوظين باستخدام memory-mapped files (memmap) وخل نفصل شويتين بوش يصير تحت الستار.
بالبداية مهم نتفق ان وجود البيانات بالRAM هو شي مثالي جدًا لكفاءة اي برنامج لان ذا الشي يخلي عندنا وصول سريع جدًا للبيانات وكذلك يسهل لنا الخربطه واللعب فيها وباداء عالي. فاللي ودنا فيه الان كيف نقدر نوصل لاداء مقارب لانها تكون عندنا طوالي بالRAM وحنا بنحفظها بالdisk؟
بنبدا بننا نحفظ هذي المتجهات بشكل متتالي وبحجم ثابت بملف مثل كذا.
[vector_1][vector_2][vector_3]...[vector_n] هذي المتجهات محفوظها بشكلها الخام البسيط ونستعمل اmmap sys call المقدم من النظام واللي يساعدنا نسوي mapping لهذا الملف للمساحة الافتراضية للذاكرة (Virtual Memory Space) وهي بختصار تجريد يربط مابين الRAM الفيزيائي الفعلي مع مساحة افتراضية ممكنه اكبر من المساحة الفعلية. ف لما نحتاج الشي يكون موجود بالRAM هذا التجريد يساعدنا بمناداة الشيء اللي نحتاجه فقط طوالي للRAM.
واللي يصير بمثال المتجهات هنا لما ننادي اmmap النظام راح يسوي mapping مابين الملف ومساحة متتالية بالمساحة الافتراضية للذاكرة ف بيكون الملف مُقطع وكل قطعة تقابلها مساحة بالذاكرة الافتراضية وغالبًا مساحة كل قطعة بتكون 4KB. ف لما نحتاج ننادي شي من الملف بدال مانرفع الملف كله للRAM بكل بساطه بس نقدر ننادي القطعة اللي نحتاجها واللي الحسبه لها بسيطة لاننا نعرف ان المتجهات محفوظه بشكل متتالي وبحجم ثابت. مثال: offset = index vector_size sizeof(float32) نقدر نرفع فيه فقط القطعة اللي نحتاجها للRAM وبكذا نكون جبنا اداء مقارب لاداء ان كل البيانات تكون بالRAM عندنا.
طيب هذا بالنسبة للمجتهات، وش يصير للPayload او الmetadata وهذا الشي فايدته باختصار احيانًا ودنا نحفظ اوصاف معينة لكل متجه تساعدنا بامور كثيرة اهمها التصفية او ممكن نحط معها بيانات مثل ids تقابل صفوف فعليه بقاعدة بيانات طبيعية والخ...
هذي الاوصاف تحفظ بKey-value store بمثال Qdrant ف هم يستعملون [RocksDB](https://rocksdb.org/) لذا الامر.
نرجع للكود.
خل نشوف ونفصل وش يصير بالملف scripts/load_to_vdb.py
اولًا نحتاج نشغل Container Qdrant وهنا انا حاطها بالdocker-compose
qdrant:
image: qdrant/qdrant:latest
restart: always
container_name: better_search_qdrant
ports:
- "6333:6333"
- "6334:6334"
expose:
- "6333"
- "6334"
- "6335"
configs:
- source: qdrant_config
target: /qdrant/config/production.yaml
volumes:
- qdrant-data:/qdrant/storage
networks:
- better_networkبعدها نربط الclient حق Qdrant
\* بالنسبة للurl اذا بتشغل الكود من داخل الcontainer ف مهم تخليه "http://host.docker.internal:6333" اذا من خارج الكونتينر "http://localhost:6333"
qdrant_client = QdrantClient(url=settings.QDRANT_BASE_URL)بعدها نسحب مجموعة من البودكاستز وجميع حلقاتهم من قاعدة البيانات عندنا وننظفهم، هنا اختارت انا مجموعة اصغر من كم بودكاست عربي ثم ارتب كل مستند (اللي بيحفظ لاحقا كمتجه) بانه يكون موجود فيه اسم البودكاست، المنتج حقه، عنوان الحلقة، وصف الحلقة. ليه؟ ابي المتجه يكون معه ذي المعلومات لتحسين دقته.
podcast_ids = list(range(50, 86)) + list(range(97, 128))
with get_db_context() as session:
logger.info(f"Loading episodes from db for {len(podcast_ids)} podcast")
episodes = get_podcast_with_episodes(podcast_ids, session)
logger.info(f"Loaded {len(episodes)} episode successfully")
logger.info("Preparing documents for embedding")
docs = [
f"{normalize_arabic(episode.podcast_name)}\n{normalize_arabic(episode.podcast_author)}\n{normalize_arabic(episode.title)}\n{clean_description(episode.description)}"
for episode in episodes
]بعدها عندنا طريقين لو نذكر حنا قلنا نبي البحث حقنا يكون مزيج مابين المفتاحي والسياقي. وفيه مصطلحين خل نتعرف عليهم.
الاول هو الDense Vectors المتجهات الكثيفة واللي هي طول اليوم نتكلم عنها واللي تكون بذا الشكل [12, -3.3, 0.24, .....] بحيث انها مليانه ارقام وهي المتجهات اللي بتكون ممتازة لحفظ السياق.
الثاني هو الSparse Vectors المتجهات المتناثرة او الخفيفة وهي المتجهات اللي بتساعدنا بحفظ الكلمات المفتاحية. هذي متجهات تكون ضخمة بضخامة عدد المفردات اللي موجود في بياناتك ف لو كان فيه 43 الف مفرد ف راح يكون حجمه وعدد الابعاد في بنفس عدد المفردات وليه تسمى متناثره لان بالعادة غالبية القيم فهذي المتجهات قيمتها صفر فقط لما نعطي جملة "مايذوق العز خمام الوسايد" فقط المواضع (indices) اللي تقابل هذي الكلمات داخل المتجه تجي لها قيمه. مثال:
[0, 0, 2.5, 0, 0, 0, 0, 1.8, 0, 0, 0, 0, 0, 3.1, 0, 0, ....., 0, 0, 0, 0, 0]طبعا لاجل الكفاءة ماتُحفظ البيانات كذا فقط تحفظ المواضع وقيمتها مثل {2:2.5, 7:1.8, 14:3.1}. وطبع القيم تحدد على حسب الخوارزمية المستخدمة وبمثالنا بنستخدم الBM25، خوارزمية من قدم الاجل سريعة، بسيطة ورهيبة وهي تشبه الtf-idf للي يعرفها لكنها حسنت عليها.
عمومًا بالنسبة للDense Vectors عندنا طريقين وهو اما استخدام نموذج محلي صغير وسريع او استخدام نموذج من نماذج OpenAI تكون اكبر وذات جودة اعلى لكنها ماهي محلية.
if embedding_type == "local":
handle_local_embeddings(
qdrant_client=qdrant_client,
collection_name=collection_name,
documents=docs,
episodes=episodes,
)
else:
handle_openai_embeddings(
qdrant_client=qdrant_client,
collection_name=collection_name,
documents=docs,
episodes=episodes,
)
وهنا بناءًا على اختيارك راح نروح بواحد من الطريقين ذول اللي بالنهاية كلهم نفس الهدف. خل نلقي نظرة على المحلي لان كوده انظف وابسط بسبب تجريد Qdrant
def handle_local_embeddings(
qdrant_client: QdrantClient,
collection_name: str,
documents: list[str],
episodes: list[EpisodeInfo],
):
qdrant_client.set_model(settings.LOCAL_EMBEDDING_MODEL)
qdrant_client.set_sparse_model(settings.SPARSE_EMBEDDING_MODEL)
if not qdrant_client.collection_exists(collection_name):
qdrant_client.create_collection(
collection_name=collection_name,
vectors_config=qdrant_client.get_fastembed_vector_params(),
sparse_vectors_config=qdrant_client.get_fastembed_sparse_vector_params(),
)
qdrant_client.add(
collection_name=collection_name,
documents=documents,
metadata=[
episode.model_dump(exclude={"description"})
for episode in episodes],
parallel=2,
ids=tqdm(range(len(documents))),
)هنا الDense Vector استعملنا [paraphrase-multilingual-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2) مهم تركز ان النموذج اللي بتستخدمه يدعم اللغة العربية. هذا نموذج بسيط وصغير وابعاده هي 384 ماتعتبر كبيرة جدًا نموذج OpenAI اللي نستعمله ابعاده 1536 وبالتاكيد كل ماكثرت الابعاد كل مازان التمثيل لكن كل مازادات المساحة كذلك فيه نموذج من OpenAI ابعاده توصل 3072 وكذلك فيه نماذج مفتوحة المصدر نفس الشي.
وزي مانشوف بالكود العملية جدًا بسيطة لتمثيل البيانات واضافتها لقاعدة البيانات وكود OpenAI كذلك بسيط لكن نضطر نسوي كم خطوه بنفسنا لان Qdrant مو حاطين دعم تلقائي لOpenAI داخل تجريدهم.
الان المفترض لما تروح http://localhost:6333/dashboard#/collections/ تلقى بياناتك موجودة.
خلاص الان كل اللي باقي بس نحط الطريقة اللي تخلي المستخدم يطلب فيها طلب ونطبق عملية البحث اللي Qdrant تشيل فيها الليلة، خل نسوي اHybridSearcher الان.
تعريف بسيط للي نحتاجه:
class HybridSearch:
def init(
self,
collection_name: str,
url: str = settings.QDRANT_BASE_URL,
mode: Annotated[str, "either 'openai' or 'local'"] = "local",
):
self.collection_name = collection_name
self.client = QdrantClient(url=url)
self.mode = mode
if mode == "local":
self.DENSE_MODEL = TextEmbedding(settings.LOCAL_EMBEDDING_MODEL)
else:
self.DENSE_MODEL = OpenAI(api_key=settings.OPENAI_API_KEY)
self.SPARSE_MODEL = Bm25(settings.SPARSE_EMBEDDING_MODEL)والان للزبدة واللي هي دالة البحث بالاول تنادي _get_query_embeddings) helper بسيطه تخلي الكود انظف للتعامل مع اذا كان المودل محلي او حق opeani
def search(self, query: str):
query_dense_vector, query_sparse_vector = self._get_query_embeddings(query)
prefetch = self._get_prefetch(
length=len(query.split()),
query=query,
query_dense_vector=query_dense_vector,
query_sparse_vector=query_sparse_vector,
)
result = self.client.query_points(
collection_name=self.collection_name,
prefetch=prefetch,
query=models.FusionQuery(fusion=models.Fusion.RRF),
limit=10,
with_payload=True,
)
response = [
HybridSearchResult(
podcast_id=r.payload["podcast_id"],
episode_id=r.payload["episode_id"],
episode_title=r.payload["document"].split("\n")[2],
podcast_title=r.payload["podcast_name"],
podcast_author=r.payload["podcast_author"],
podcast_categoires=r.payload["podcast_categories"],
sim_score=r.score,
)
for r in result.points
]
return responseبعدين بتنادي helper ثانية تخلي الكود انظف. الPrefetch هي طريقة نقدر نوضح فيها وش الاشياء اللي نبي نطلبها ونناديها من قاعدة البيانات وبناءًا على وش نبي البيانات ترجع لنا، وبعدين Qdrant بتتولى مهمة البحث وتتاكد انها تنادي الامور بالطريقة والترتيب اللي اتخذناه. ف هنا نقدر نفصل ونختار متى نبي نستخدم المتجهات الكثيفة ومتى المتناثرة وكيف نمزج بينهم وكم العدد اللي نبي القاعدة ترجعها لنا وتفاصيل اخرى. (يمدي نطلب بحث من نفس المتجه احيانًا مثل مانشوف لما يكون الطول اقل من ثلاثة نستعمل المتناثرة فقط مرتين بس نضيف عامل تصفية بالمرة الاخرى). وبعدها يجي المزيج باننا نبحث بكل الطريقتين السياقي والمفتاحي ونمزج بينهم بالنهاية باستخدام الFusion الموجود بالquery_points النهائية وبنشوف صورة شوي توضح وش يصير بالضبط.
def getprefetch(
self,
length: int,
query: str,
query_dense_vector: list[float],
query_sparse_vector: list[float],
):
if length <= 3:
prefetch = [
models.Prefetch(
query=models.SparseVector(**query_sparse_vector.as_object()),
using="bm25",
limit=40,
params=models.SearchParams(hnsw_ef=256, exact=True),
),
models.Prefetch(
query=models.SparseVector(**query_sparse_vector.as_object()),
using="bm25",
limit=40,
params=models.SearchParams(hnsw_ef=256, exact=True),
filter=models.Filter(
should=models.FieldCondition(
key="documents", match=models.MatchAny(any=query.split())
)
),
),
]
else:
prefetch = [
models.Prefetch(
query=query_dense_vector,
using=(
"openai"
if self.mode == "openai"
else "fast-paraphrase-multilingual-minilm-l12-v2"
),
limit=15,
params=models.SearchParams(
hnsw_ef=256,
exact=True,
),
),
models.Prefetch(
query=models.SparseVector(**query_sparse_vector.as_object()),
using="bm25",
limit=40,
params=models.SearchParams(hnsw_ef=256, exact=True),
),
models.Prefetch(
query=models.SparseVector(**query_sparse_vector.as_object()),
using="bm25",
limit=40,
params=models.SearchParams(hnsw_ef=256, exact=True),
filter=models.Filter(
should=models.FieldCondition(
key="documents", match=models.MatchAny(any=query.split())
)
),
),
]
return prefetch
طبعا هنا عندي شرط بسيط اذا كان البحث اقل من 4 كلمات ف بنستخدم بس بحث مفتاحي لان غالبًا بيكون ادق وافضل لكن اذا بدا يكثر هنا نبدا نستخدم المزيج.
فيه طريقتين للتعامل مع نتائج البحثين عشان نقدر ندمجهم سوا، الاول وهي اللي نستعملها الFusion او المزيج فكرتها باختصار تدمج بناءًا على النتائج اللي ترجع من البحث، فالمتجهات اللي رجعت بتشابه عالي هي اللي بترجع بالنتيجة النهائية.
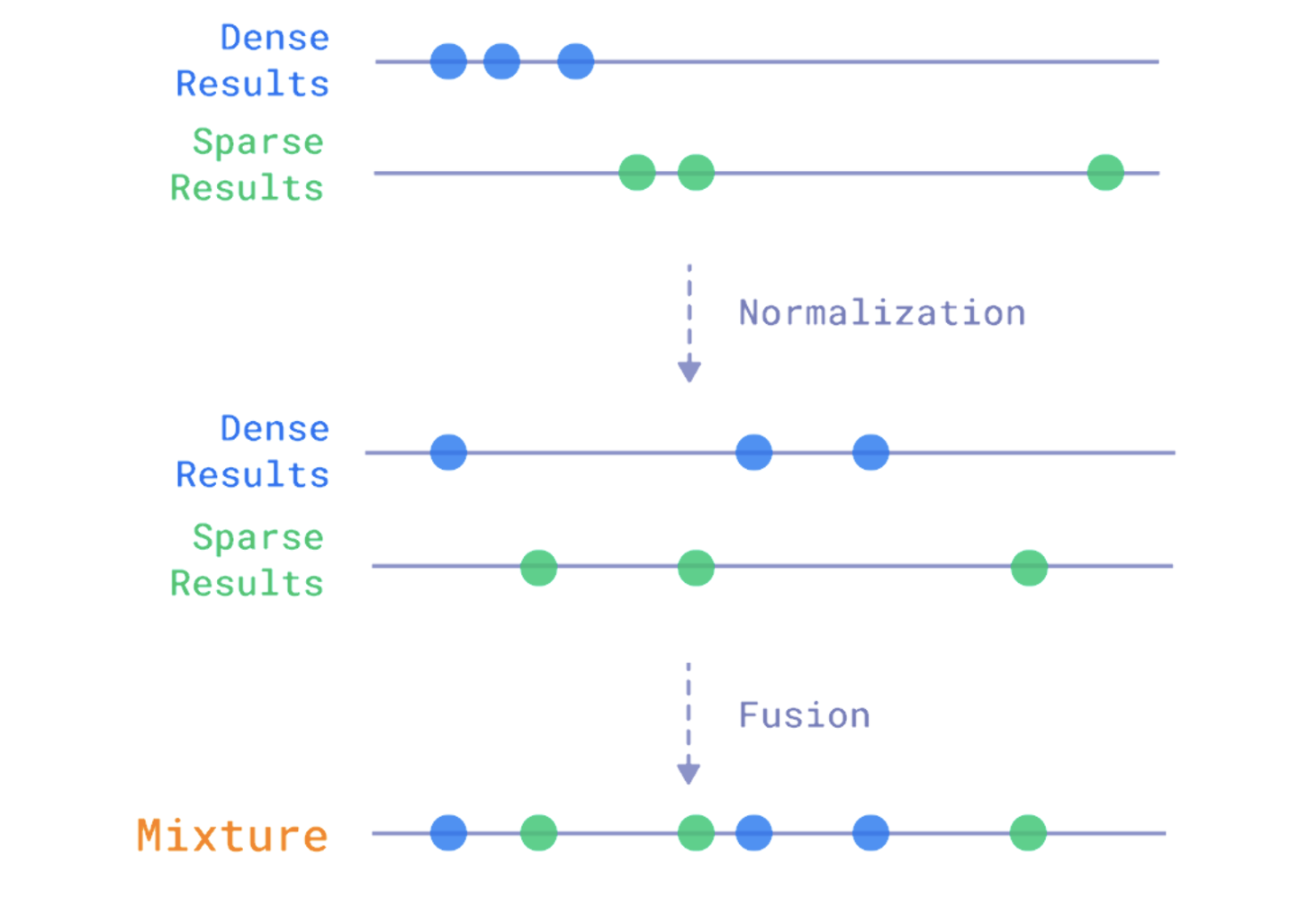
الطريقة الثانية واللي ما استخدمناها هي اعادة التدريب (Re-ranking) والفكرة منها انه بالغالب يكون فيه نموذج وظيفته الاساسيه هي انه يعيد الترتيب بناء على مو بس النتيجة بل معالجة جديدة لكل المتجهات وكم شي اخر.
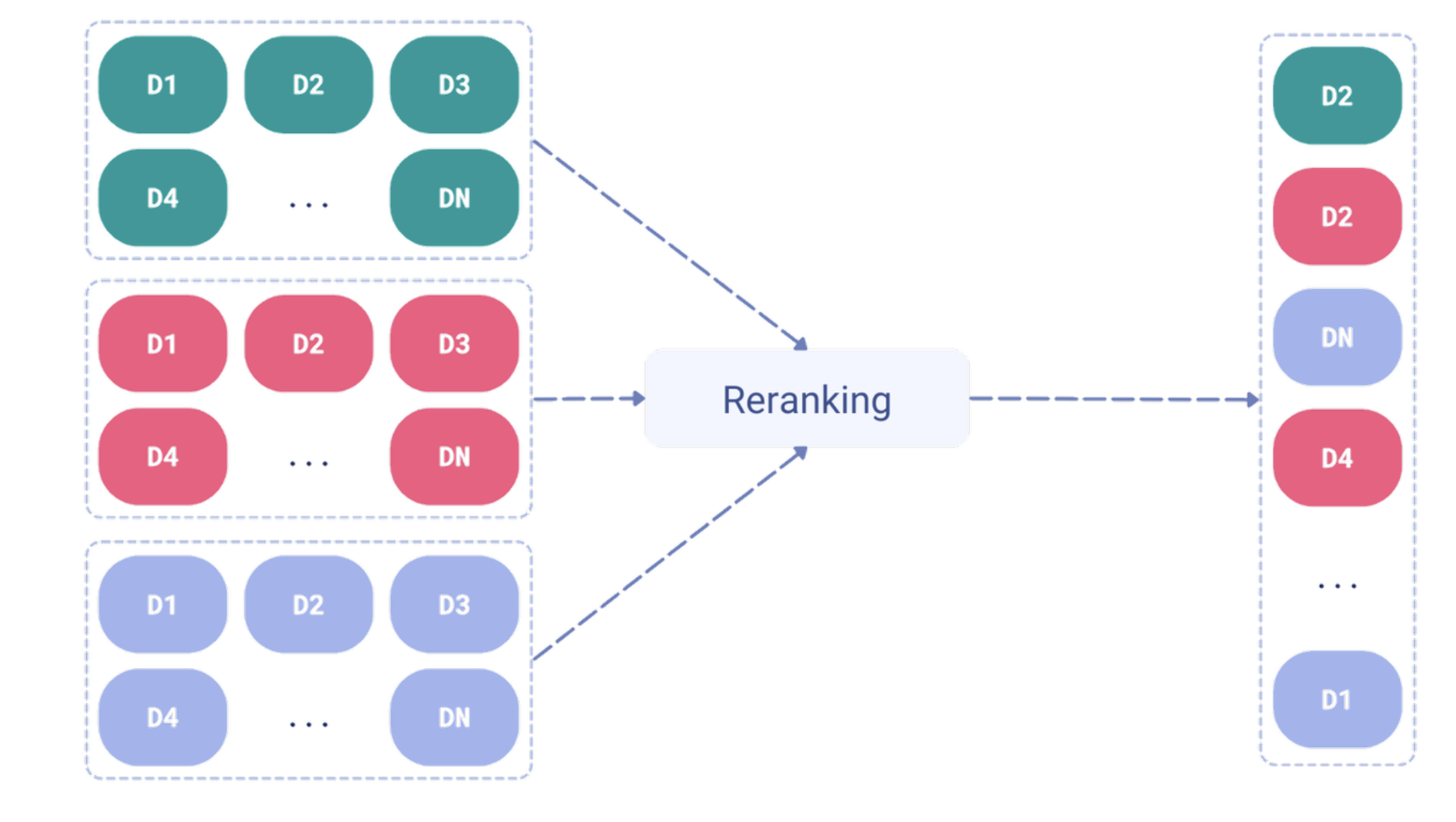
كل الطريقتين لها ميزاتها وسلبياتها ف مثلًا الاولى اسرع لكن قد تفقد بعضًا من الدقة والثانية ادق لكن ابطئ.
صحيح سكبنا كم شغله بالكود لكن كله موجود ويمديك تشيك عليه بالريبو وفعليا دام وصلنا ذا المرحلة ف حنا خلاص طبقنا المحرك بكل ذي البساطة والشكر طبعا لQdrant اللي شالت الليله. يمديك الان تربطه بAPI و Frontend وخلاص صار عندك محرك بحث ممتاز. طبعا كود الAPI والFrontend عندي كود تسليكي وبس عشان نشغل ديمو ف لاتعتمده.
ف خل نبحث مثلًا عن "حلقة جادي عن اصل المال".
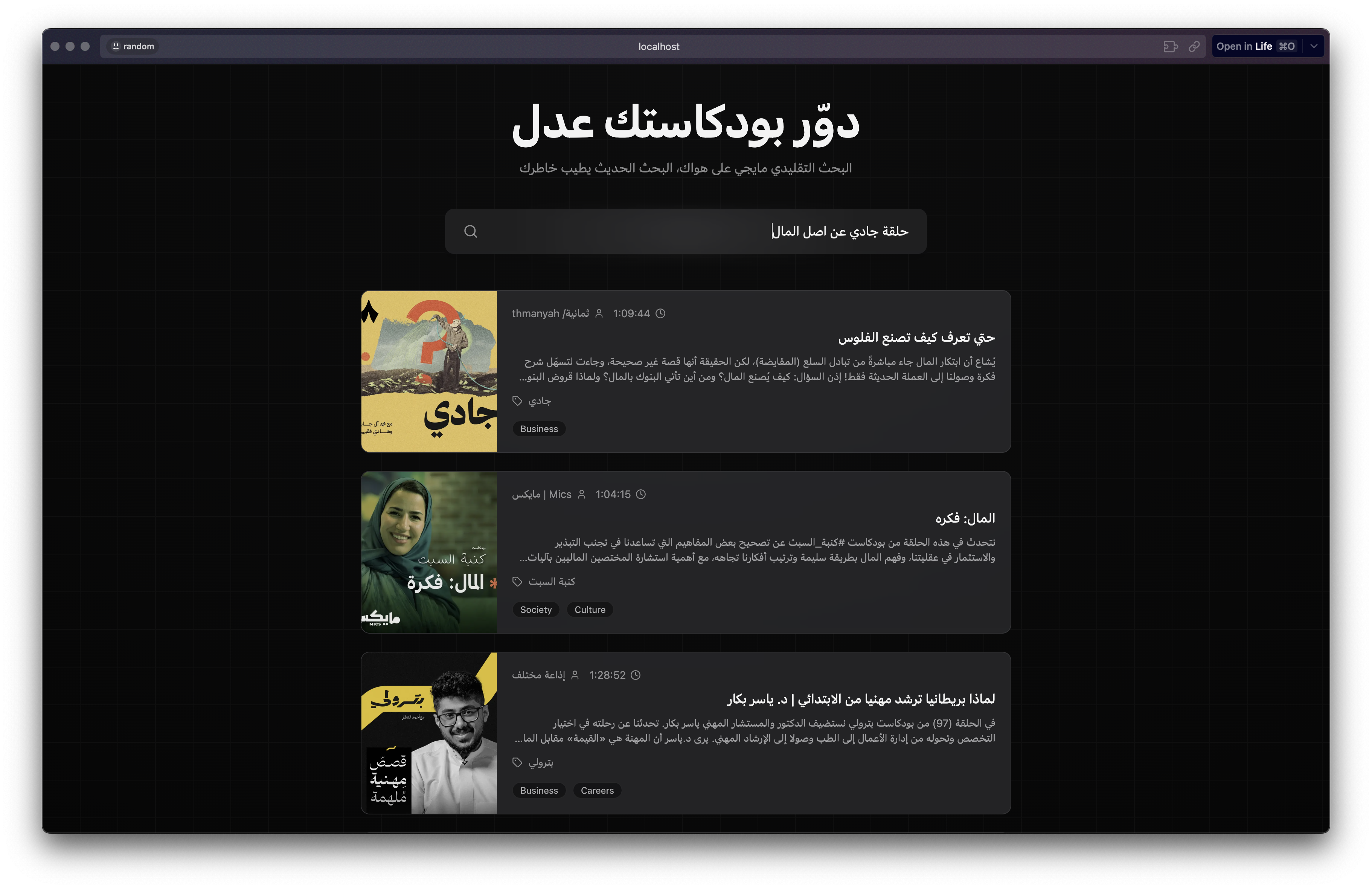
ونلقى اللي نبيه بالرغم من ان كلمة اصل المال نفسها ماهي موجودة لا بوصف الحلقة ولا بعنوانها. ولو نشوف نفس البحث في راديو ثمانية و ابل بودكاست مابنلقى الحلقة المبتغاة.
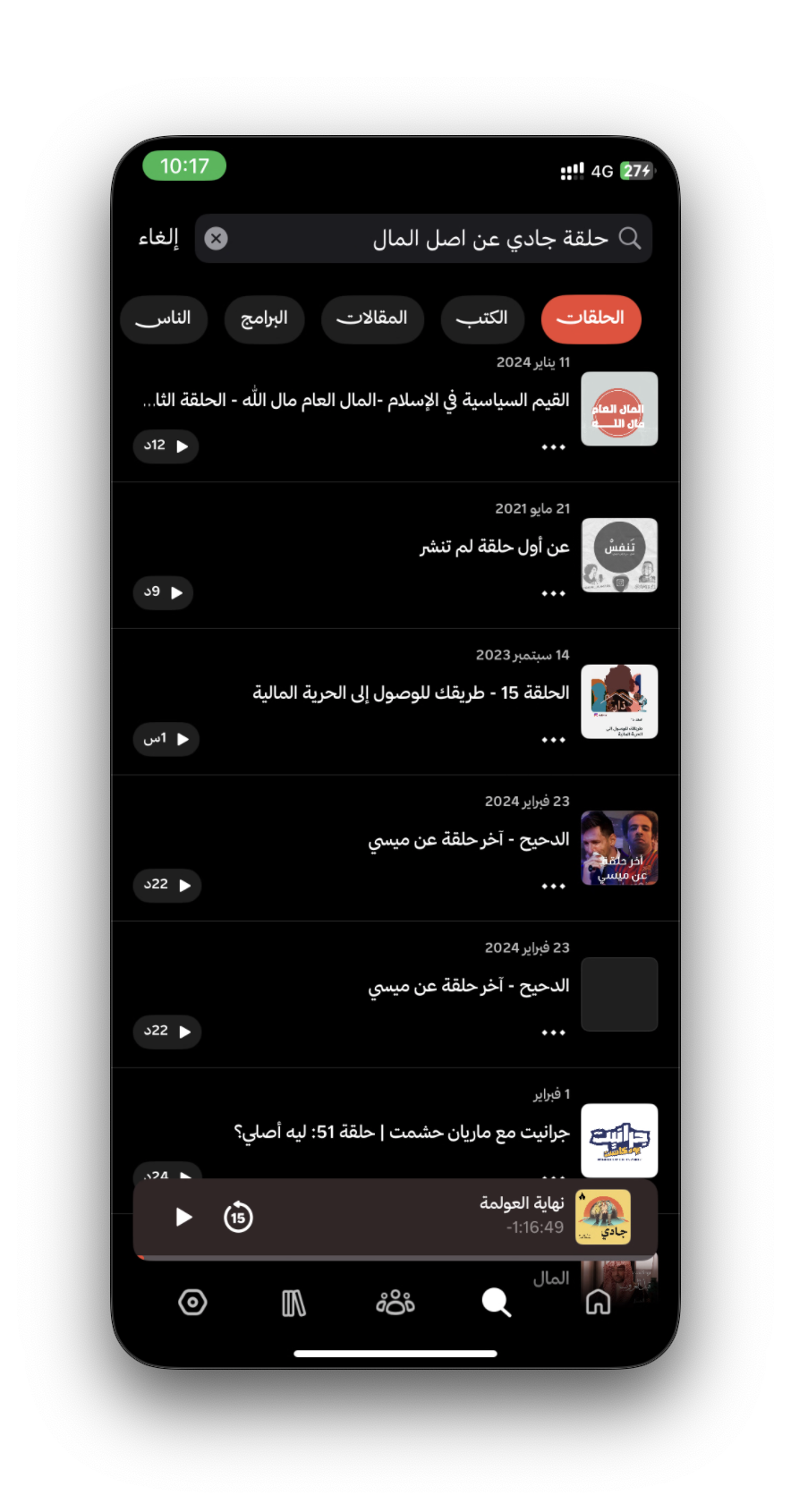
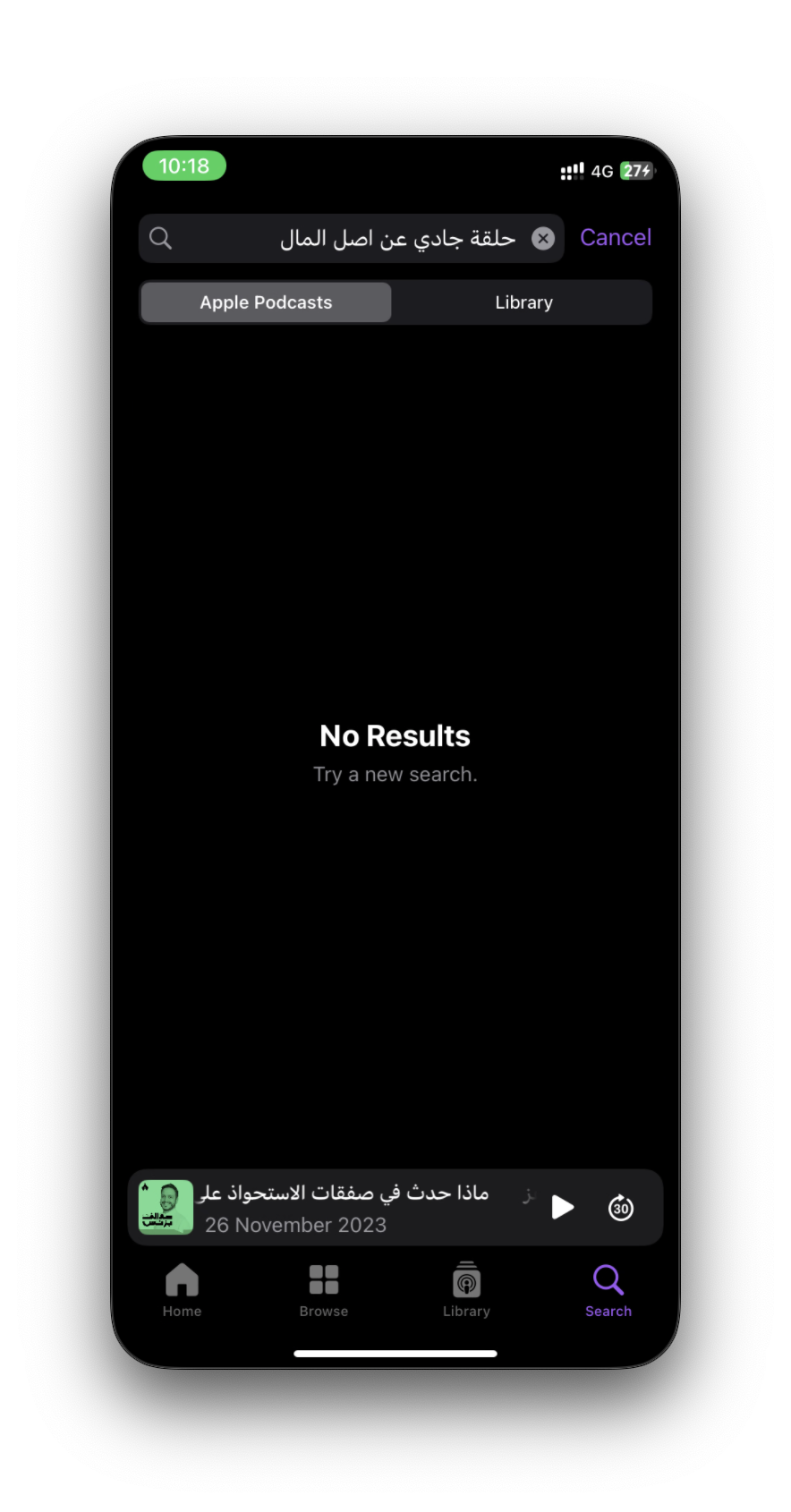
ويمدينا نجرب اكثر من تجربة لكن اعتقدت وضحت الفكرة اللي لها ايجابيتها واحيانًا سلبياتها بانها ماتنجح لانها قيمت اكثر من حلقة تقييم سياقي عالي. لكن فالغالب تجيب المبتغى بطريقة افضل من البحث التقليدي. طبعا فيه تحديات بتطبيقها وجودتها على سكيل كبير مثل ماشفنا الPodcastIndex فيه اكثر من 100 مليون حلقة وممكن مع ذا الرقم الكبير تبدا تتدنى جودة البحث السياقي.
افكار شيقة يسوى البحث فيها: حنا حاليًا فقط نمثل وصف الحلقة، ماذا لو مثلنا الحلقه كلها؟ خذينا التفريغ النصي للحلقه ومثلناه بالكامل ف لما نجي نبحث عن شي شفناه بشورت ولا ريل هل نقدر نلقاه حتى سؤالنا ماهو موجود لا من قريب ولا من بعيد بعنوان ووصف الحلقة؟ (طبعا السكيل حقها مجنون وغير منطقي البته لكن شيق النظر بالموضوع).
نقاط شيقة

الصورة هذي هي تمثيل لمتجهات 3000 حلقة، لما نجي ونلقي نظرة قريبة لها بنكتشف اشياء شيقة من اللي تعلمناه بالبداية عن المتجهات والتمثيل.
ف خل نمسك وحده من ذي التمثيلات ونشوف وش الحلقات اللي تجمعت سوا.
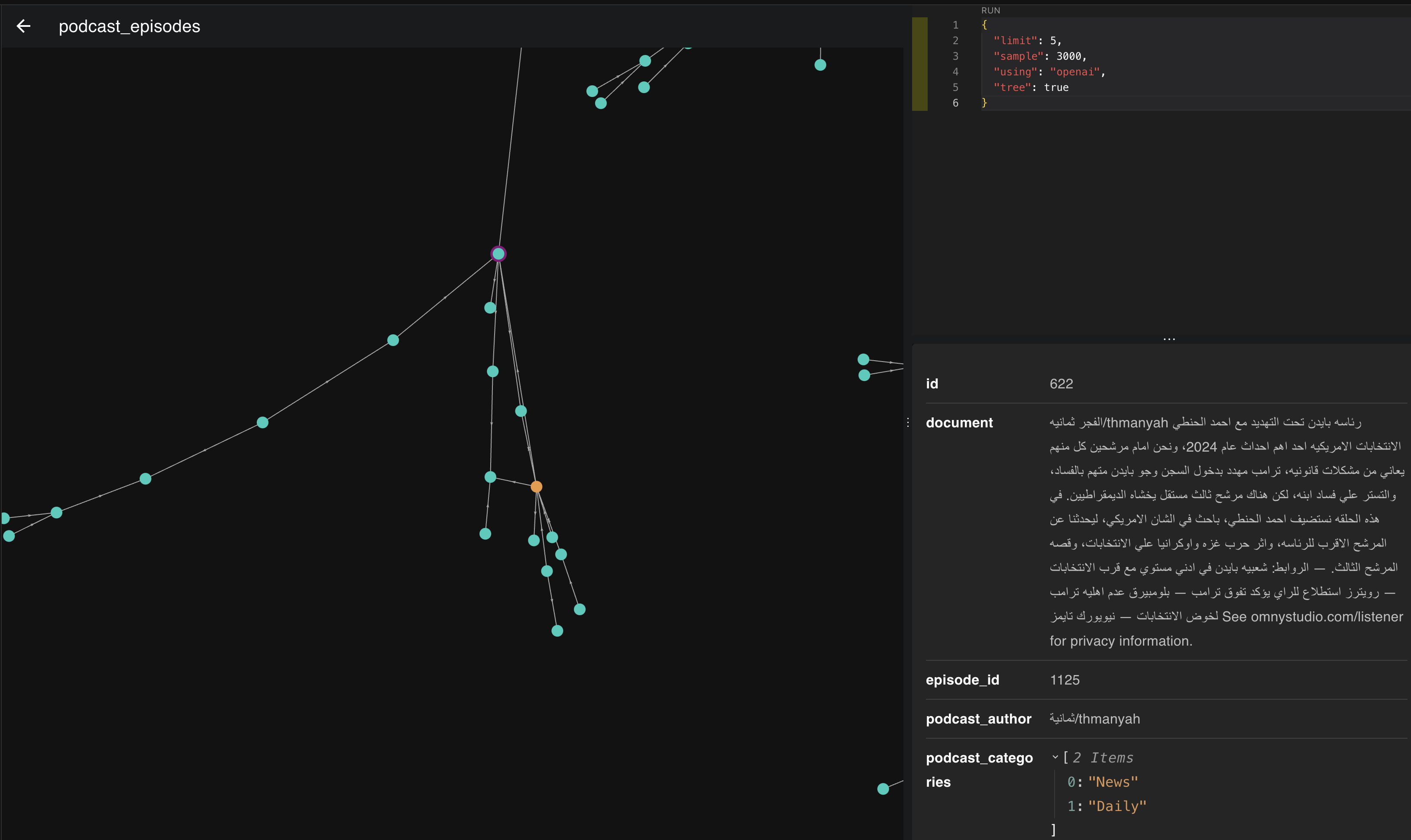
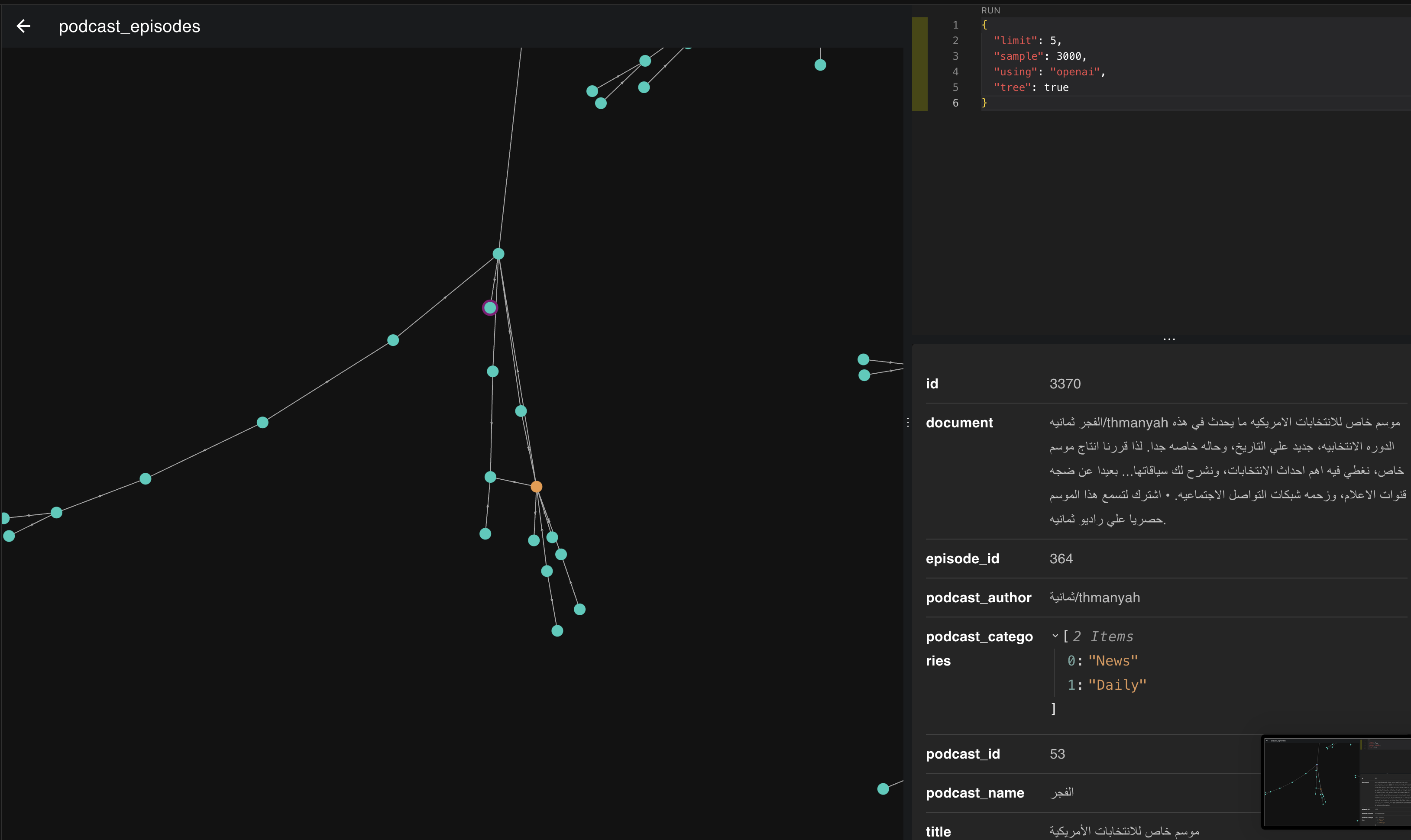
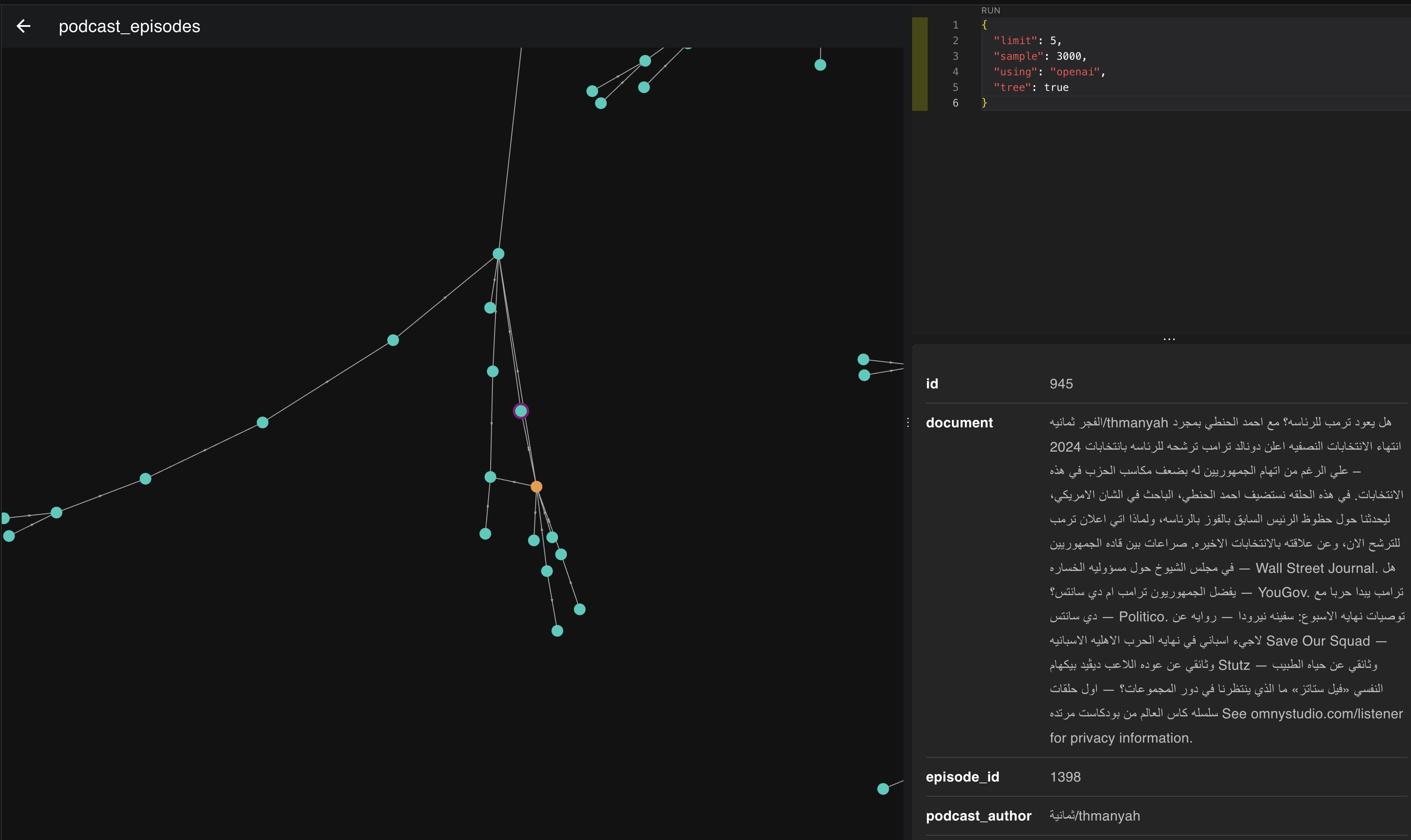
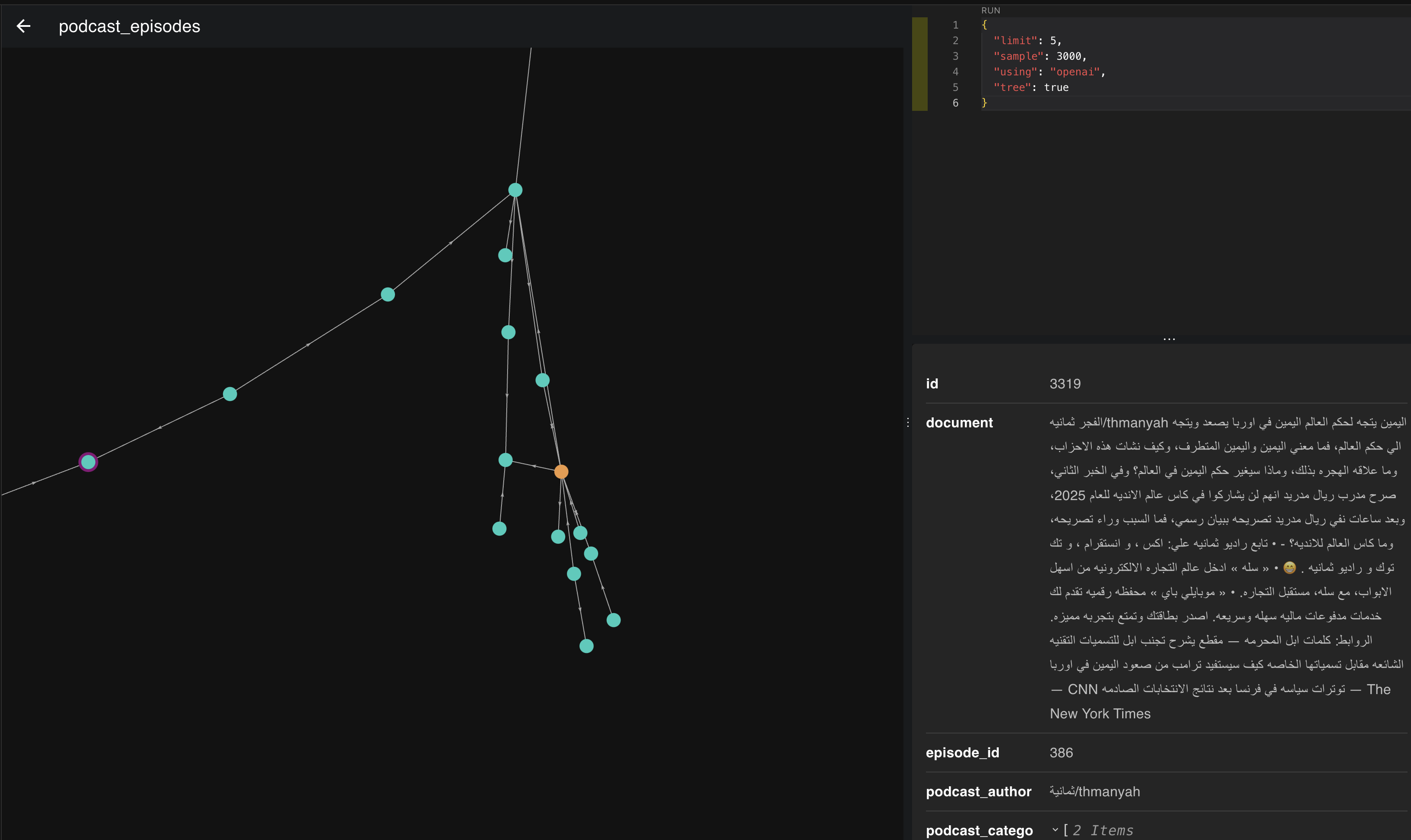
ف لو نشوف بالصورة اللي فوق نلقى ان الحلقات اللي تجمعت بذا المكان والاتجاه كلها تتكلم عن السياسة ورئيس الدولة ف كل م اتجهنا يمين تحت قعدنا نتكلم عن امريكا ورئيسها واذا يسار قليلًا نبدا نروح لاوروبا ورؤسائها.
وطبعا هذا تطبيق اخر اراه عظيم للمتجهات والتمثيلات واللي هو بانهم يساعدونك تبني انظمة توصية ممتازة جدًا ف اذا شفت المستخدمين يسمعون حلقات معينة بكثرة يمديك توصي له الحلقات المجاورة وتعطيه تجربه مميزة.
الزبدة
طبعا يطول الكلام والاستنتاجات اللي يمدي نطلع فيه بهذا الموضوع لكن راح نوقف هنا. اتمنى وضحت الفكرة الاساسية والفائدة العظمى من وجود المتجهات والتمثيلات وهذا كان مجرد زاوية واحدة من النظر لذا الموضوع.
القادم افضل.

أنا ممدوح، مهندس ذكاء إصطناعي واحب ابني منتجات تحل مشاكلي. أساهم ببناء أكبر مكتبة محتوى عربي في ثمانية.